Data Scraping mit Data Miner als Browser-Erweiterung: Analysiere Social-Media-Performances


Data Miner ist eine Browser-Erweiterung, die Daten aus Website-Oberflächen scrapen – also schaben kann. Für Trendanalysen im Social-Media-Bereich können so Likes, Kommentare und Texte aus Posts extrahiert werden, um die Daten in einer Zeitachse darzustellen.
Data Scraping ist ein einfacher, aber sehr effektiver Ansatz für die Analyse von Social-Media-Kanälen. Damit werden Daten von der Oberfläche einer Website mit dem Scraper gesammelt und diese anschließend in einer Excel- oder CSV-Datei ausgegeben. Im Falle von Social-Media-Posts wären das zum Beispiel Gefällt-mir-Angaben, Kommentare, Beitragstexte und das Datum des Posts. Damit können wir einfach und entspannt Social-Media-Kanäle von Unternehmen und Mitbewerbern auf ihre Performance hin untersuchen und erfahren, welcher Account besonders erfolgreiche Strategien verwendet und die meisten Interaktionen auf den Posts verzeichnet.
Dabei gibt es einen großen Unterschied zu den herkömmlichen Social-Media-Analysen, die aus den verschiedenen Softwares in dem Bereich erhältlich sind: Diese arbeiten nämlich nicht mit Scraping, sondern sind API-basiert. Das heißt, sie schalten sich an die Programmierschnittstelle der jeweiligen Plattform zu und rufen von dort direkt die Daten für den untersuchten Social-Media-Account ab. Das hat in der Regel zwei Nachteile: Erstens limitieren die Plattformen (Facebook, Instagram, Twitter) den Abfragezeitraum für Posts und Accounts relativ stark, sodass man je nach Preismodell vielleicht 7 Tage oder 28 Tage rückwirkend eine Performance einsehen kann. Und zweitens kosten die Tools je nach Datentiefe immer mehr, weil für API-Abrufe Gebühren fällig werden, die das Social-Media-Tool an die Plattformen entrichtet. Wer ein gutes Paket kostenpflichtig einbucht, kann so vielleicht einen Mitbewerber-Account für ein Jahr rückwirkend auf Performances hin analysieren – ein noch längerer Zeitraum würde noch mehr Geld kosten oder gar nicht vorhanden sein.
Du hast eine frage?
Stelle deine Frage
Tiefenanalysen und volle Unabhängigkeit via Data Scraping mit Data Miner
Data Miner kostenlos als Browser-Erweiterung »
Data-Scraping-Ansätze sind für die Analyse von Posts im Zeitverlauf wesentlich kostengünstiger und in den meisten Fällen kostenlos, weil wir sie selbst bedienen und steuern können. Außerdem lassen sich Trendverläufe in unbegrenzten rückwirkenden Zeiträumen messen, weil Data Scraper schlicht jeden Post bis zum allerersten abgesetzten Post durchgehen können. Sprich – sie sind nicht durch eine kostenpflichtige Plattform-API limitiert, was dem Anwender wiederum ein hohes Maß an Unabhängigkeit gibt.
Mit der Browser-Erweiterung Data Miner für Google Chrome ist das bereits im kostenlosen Paket möglich. Stand 2022 zeichnet sich Data Miner darin aus, dass die Anwendung nicht über ein installiertes Programm läuft, sondern als Erweiterung direkt über den Browser. Gleichzeitig ist Bedienung wesentlich einfacher als in den Scraping-Anwendungen der letzten Jahre. Dafür ist aber auch der Funktionsumfang im kostenlosen Paket geringer, als zum Beispiel beim Web-Scraping-Tool Octoparse, welches die Möglichkeit für komplexe und fortgeschrittene Scraping-Funktionen bietet – wie etwa das Anklicken von Elementen, das Ausfüllen von Kontaktformularen, die Eingabe von Daten und das automatisierte Ausführen von Befehlen an unterschiedlichen Tagen. Für die Analyse von Beitragsreaktionen bei LinkedIn reicht Data Miner aber vollkommen aus, und es ist sehr praktisch, dass gerade Einsteiger nicht mit einer gewaltigen Komplexität überhäuft werden.
Anwendungen im Bereich Data Scraping benötigen immer unsere Konfiguration von unserer Seite. Sprich: Wir müssen dem Scraper einen Fahrplan für die Website-Bedienung mitgeben, damit er sich durch die Website-Elemente navigieren kann. Das Scraping funktioniert nämlich in Echtzeit und die Anwendung extrahiert die Daten Post für Post einzeln.
In der Regel brauchen Scraper drei zentrale Eingaben:
- Rows (Reihen) sind die Dateninhalte der späteren Excel-Tabelle und ergeben sich aus den Feldern der Website-Elemente, die wir für das Scraping einstellen
- Columns (Spalten) sind die konkreten Daten, deren Sammlung wir im Scraper einstellen und die in den Spalten der späteren Excel-Tabelle sortiert auftauchen sollen
- Navigation ist wichtig, wenn unbestimmte Scroll-Bewegungen durchgeführt werden müssen oder Seiten (Pagination) umgeschaltet werden sollen, um die gesamte Bandbreite der Social-Media-Posts zu scrapen. Gegebenenfalls ist eine Loop-Funktion erforderlich, damit der der Scraper beim Kontakt mit einem Navigationselement immer wieder neu ausführt, bis er kein Navigationselement mehr findet.
Schritt 1 – Data Miner installieren und aufrufen
Sobald ihr euch Data Miner als kostenlose Browser-Erweiterung in Google Chrome installiert habt, könnt ihr auf einen gewünschten Social-Media-Account gehen und die Erweiterung aufrufen. Klickt anschließend auf den blauen Button Scrape This Page.
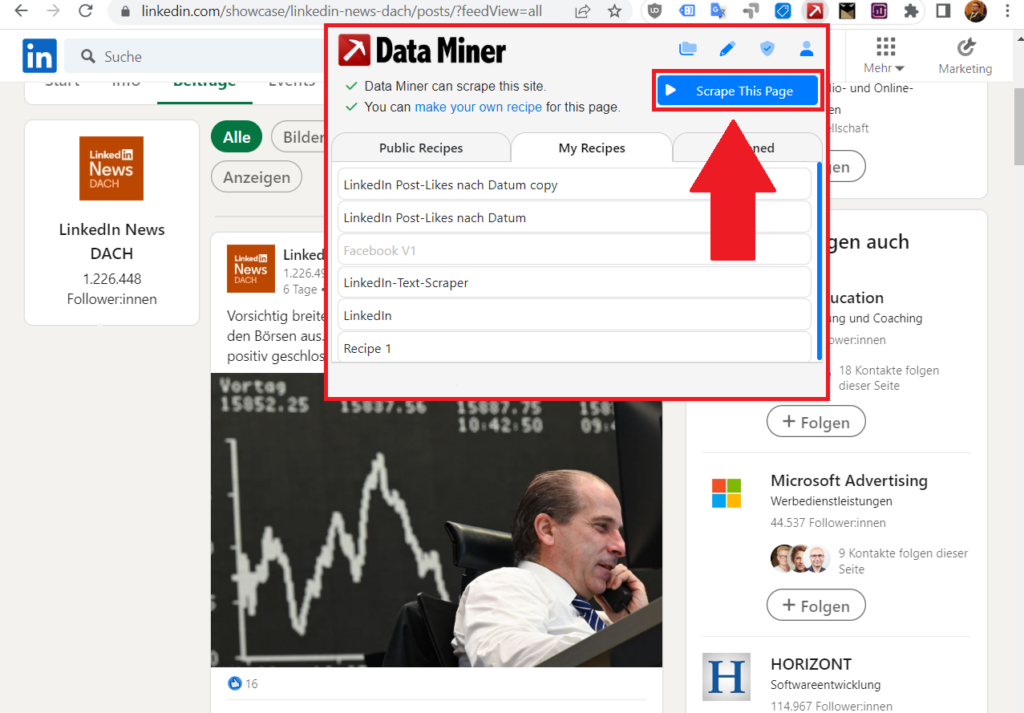

Klickt in der linken Menüleiste auf New Recipe und anschließend auf den blauen Button im Hauptfenster + New Recipe.
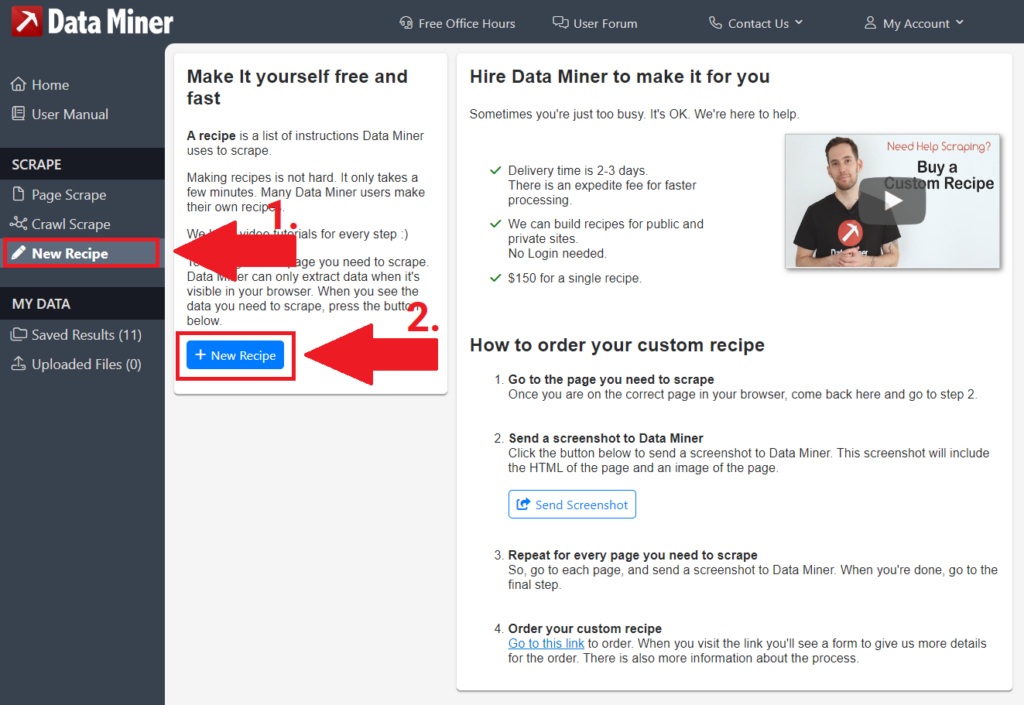

Schritt 2 – Multiple Rows von Data Miner
Geht nun im sich öffnenden Fenster auf den zweiten Reiter oben mit dem Titel Type. Hier müsst ihr nichts weiter beachten, die voreingestellte Auswahl für “mulitple rows” ist für Social-Media-Accounts bereits die richtige.
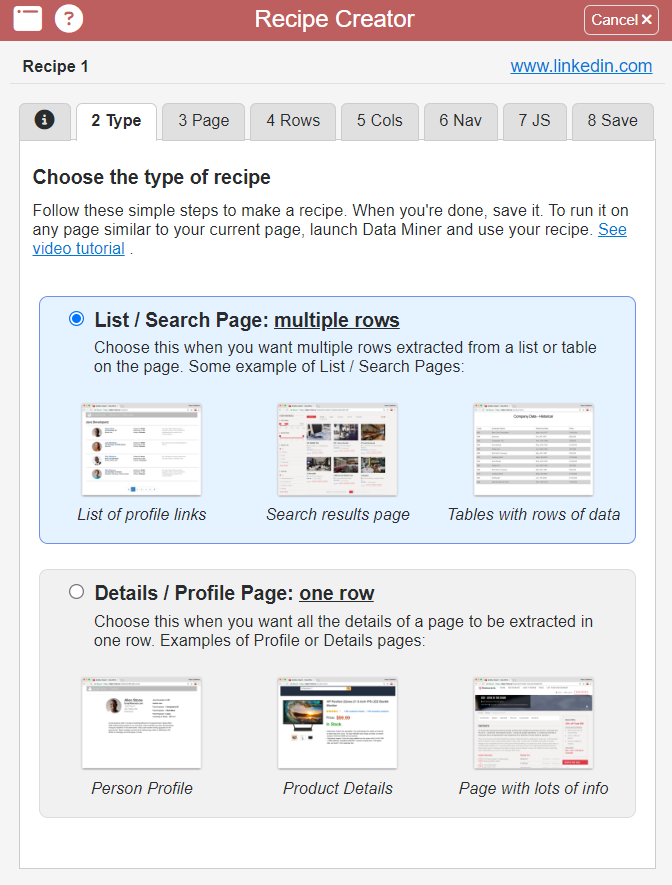

Schritt 3 – Page & Easy Row Finder von Data Miner
Geht nun oben auf den dritten Reiter mit dem Titel Page und klickt auf den Button Easy Row Finder. Das ist nun einer von von drei entscheidenden Schritten, um dem Scraper den Fahrplan für die Bedienung mitzugeben.
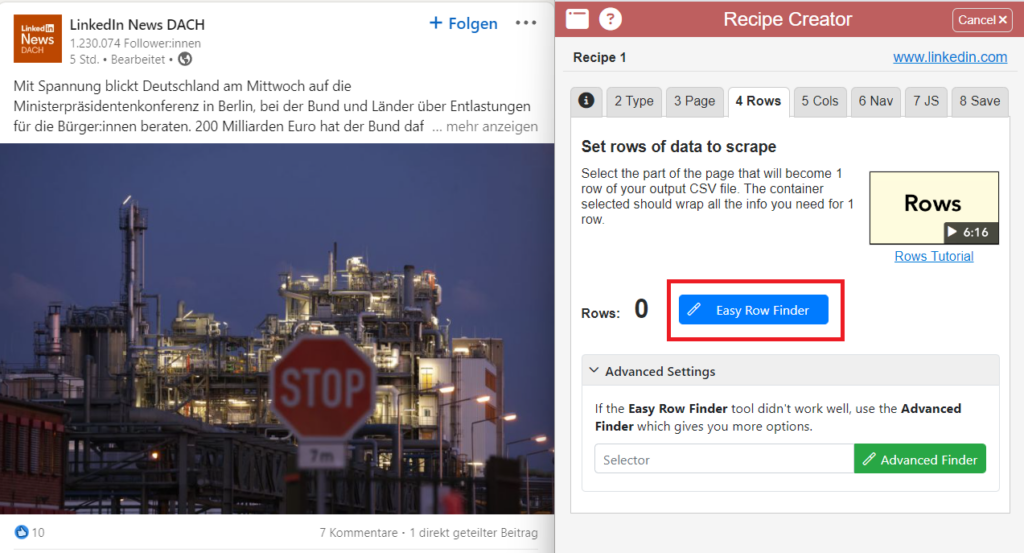

Wähle nun mit der Maus einen gesamten Post aus. Die Auswahl der Fläche wird währenddessen in roter Farbe eingeblendet. Tippe anschließend die Zahl 1, um die Auswahl zu bestätigen.
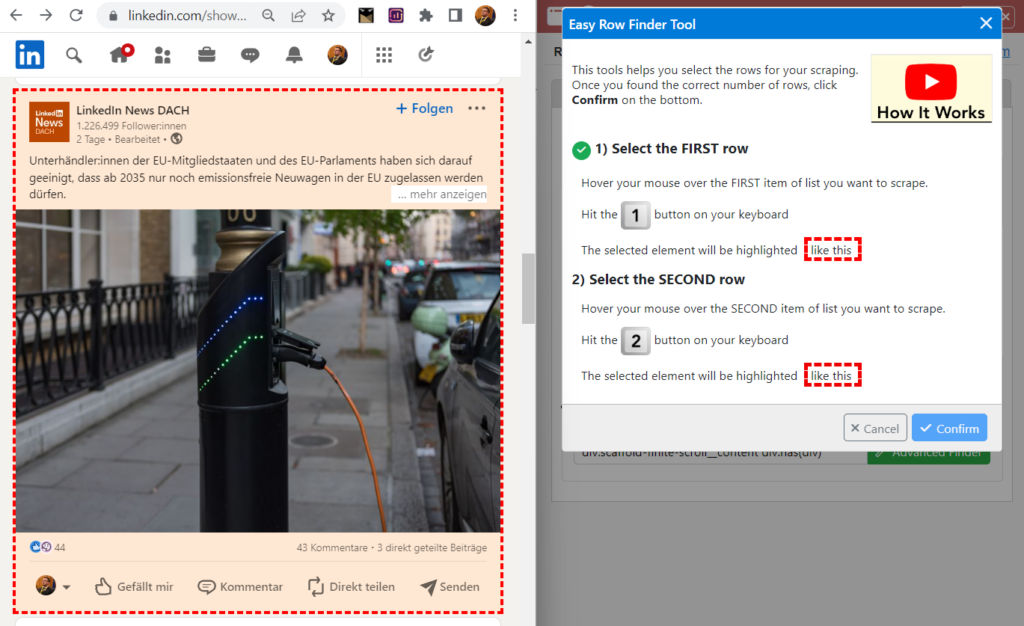

Wähle nun auf einem zweiten Post ein weiteres Element mit der Maus aus und tippe die Zahl 2, um die Auswahl zu bestätigen. Das dient dazu, dass alle Posts in der Auswahl für die Rows (Reihen) erfasst werden.
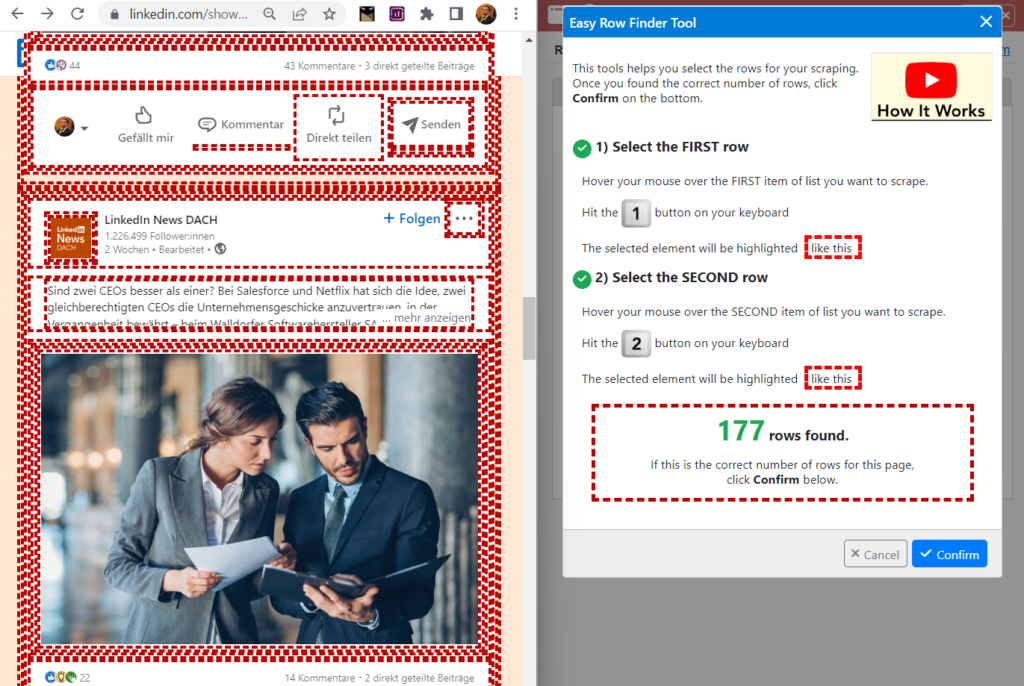

Du hast eine frage?
Stelle deine Frage
Schritt 4 – Columns & Easy Column Finder von Data Miner
Nun müssen wir Columns (Spalten) festlegen. Diese speichern in der späteren Excel- oder CSV-Tabelle die konkreten Daten, die aus den Posts extrahiert werden sollen. In diesem Fall wären dies: Die Anzahl der Beitragsreaktionen und die Datumsangaben der jeweiligen Beiträge, um die Performance im Zeitverlauf nachzuvollziehen. Klickt dazu auf den den Reiter 5 Cols oben und erstellt zwei Columns.
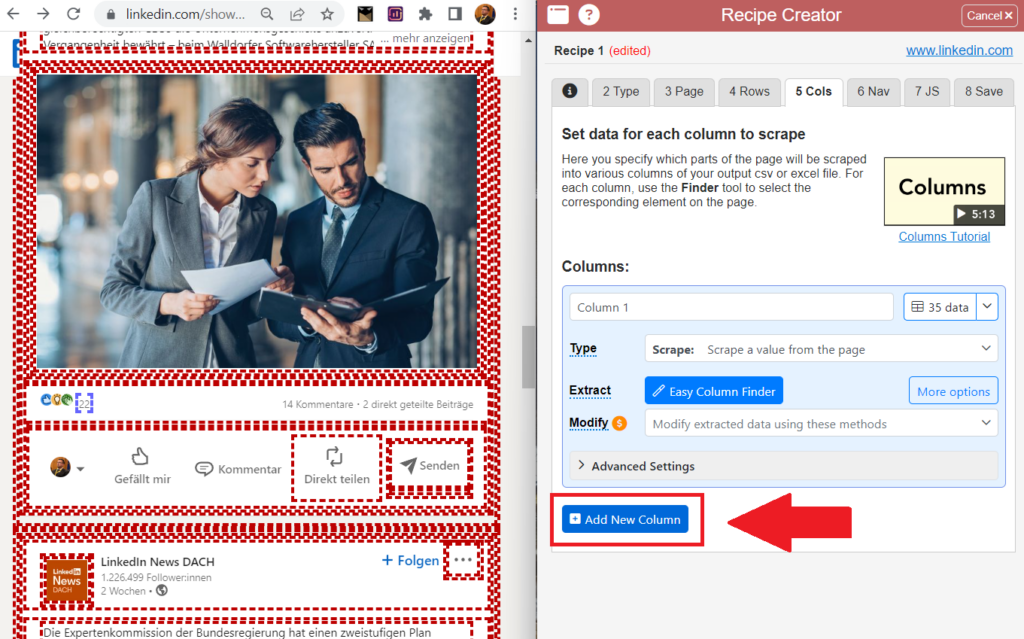

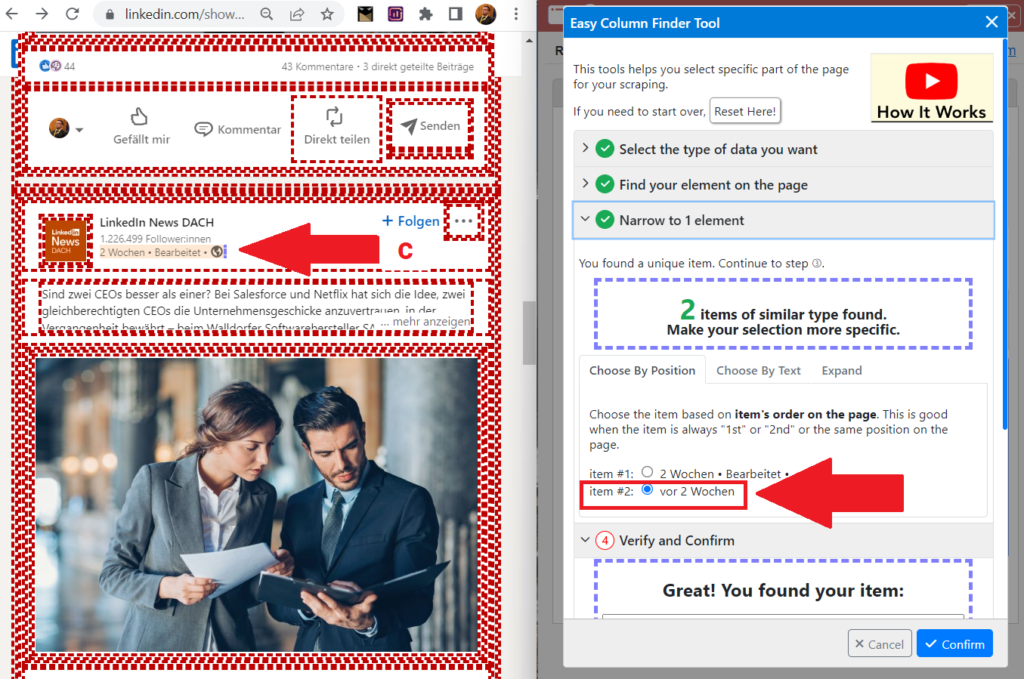
Klickt nun auf den Button Easy Column Finder, und klickt führt den Mauszeiger an das Element im LinkedIn-Beitrag, das die Daten für jede der Spalten enthält und tippt den Buchtaben C.
1) Column 1: Beitragsreaktionen (Mauszeiger heranführen und C tippen)
2) Column 2: Datum (Mauszeiger heranführen und C tippen)

Schritt 5 – Navigation festlegen mit Easy Nav Finder von Data Miner
Jetzt muss nur noch das Bedienelement für die Navigation gefunden werden, damit beim Scraping mehr Posts erfasst werden als nur die, die aktuell auf der geladenen Website sichtbar sind. Die Festlegung des Navigationselements geschieht über den Reiter 6 Nav oben in der Menüleiste von Data Miner.
Klickt dazu auf den Button Easy Nav Finder. Im Fall von LinkedIn-Beiträge lässt sich für diesen Zweck kurz die Internetverbindung trennen, herunterscrollen, bis der Button “Weitere Ergebnisse anzeigen” sichtbar wird, und dann mit dem Mauszeiger und der Taste N das Navigationselement als solches festlegen.
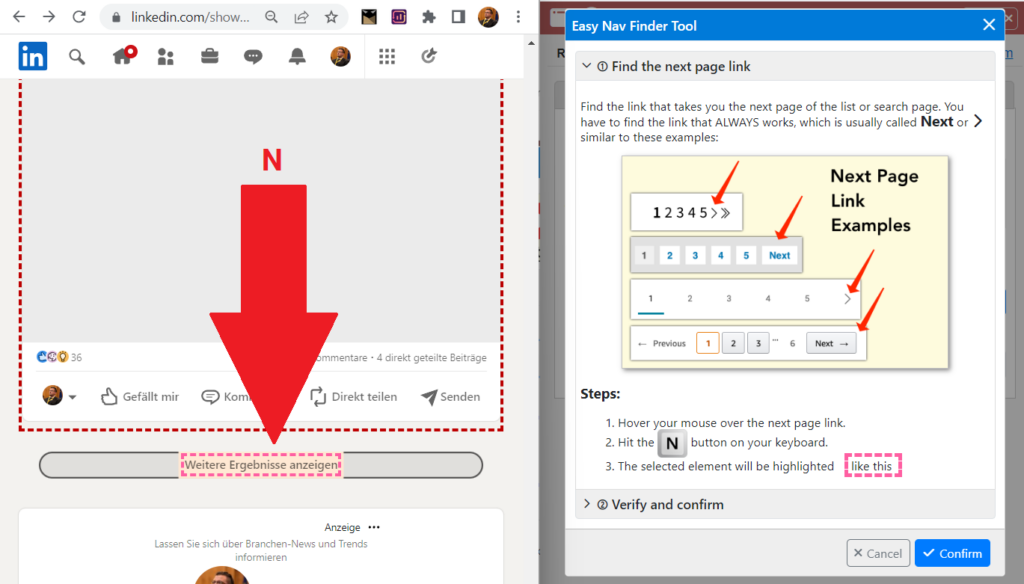

So sieht es dann aus, wenn das Navigationselement erfolgreich gefunden wurde.
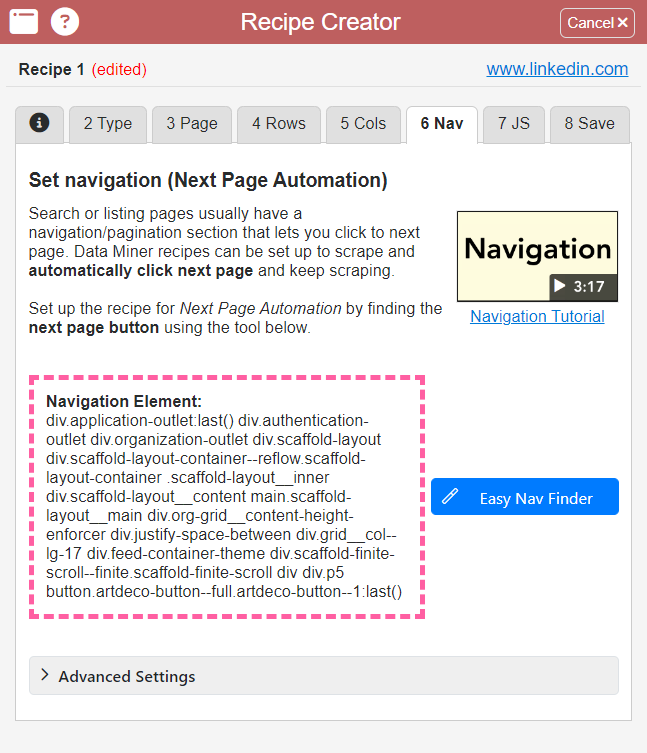

Fast fertig: Im obigen Reiter 8 Save lässt sich nun der Scraping-Fahrplan benennen, speichern und starten. Scrollt vorher in den LinkedIn-Beiträgen so tief wie möglich herunter, sodass so viele Beiträge wie möglich geladen sind.
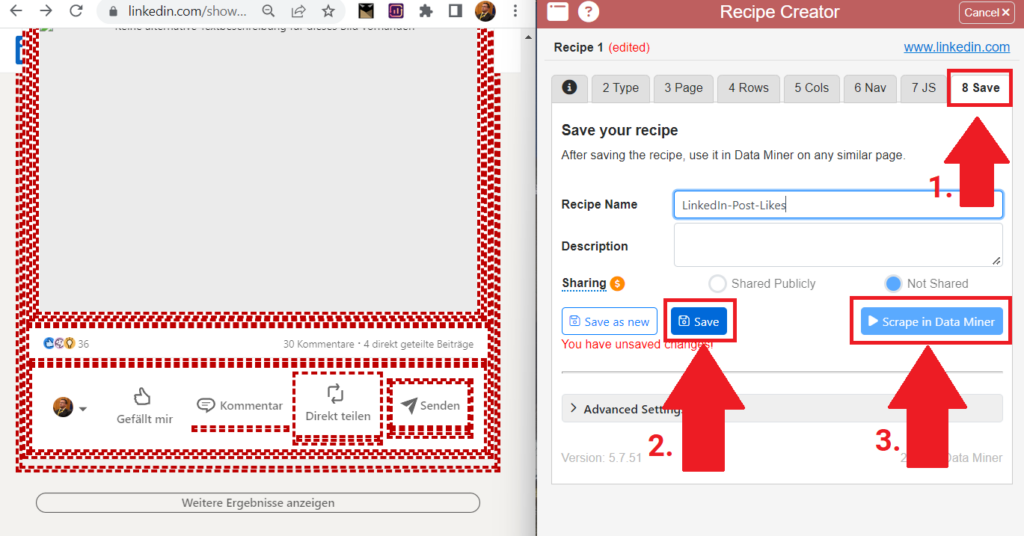

Klickt nun auf Scrape and Append.
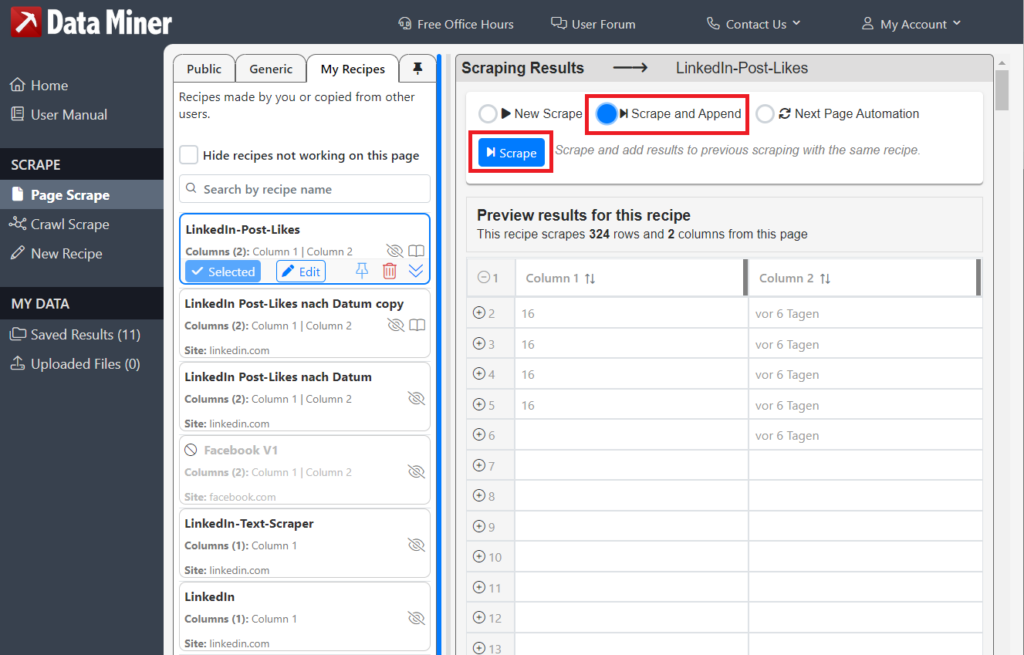

Wenn alles geklappt hat, sollte Data Miner die Posts mindestens in der Datentiefe gescraped haben, die ihr in der Website mit den LinkedIn-Beiträgen geladen habt.
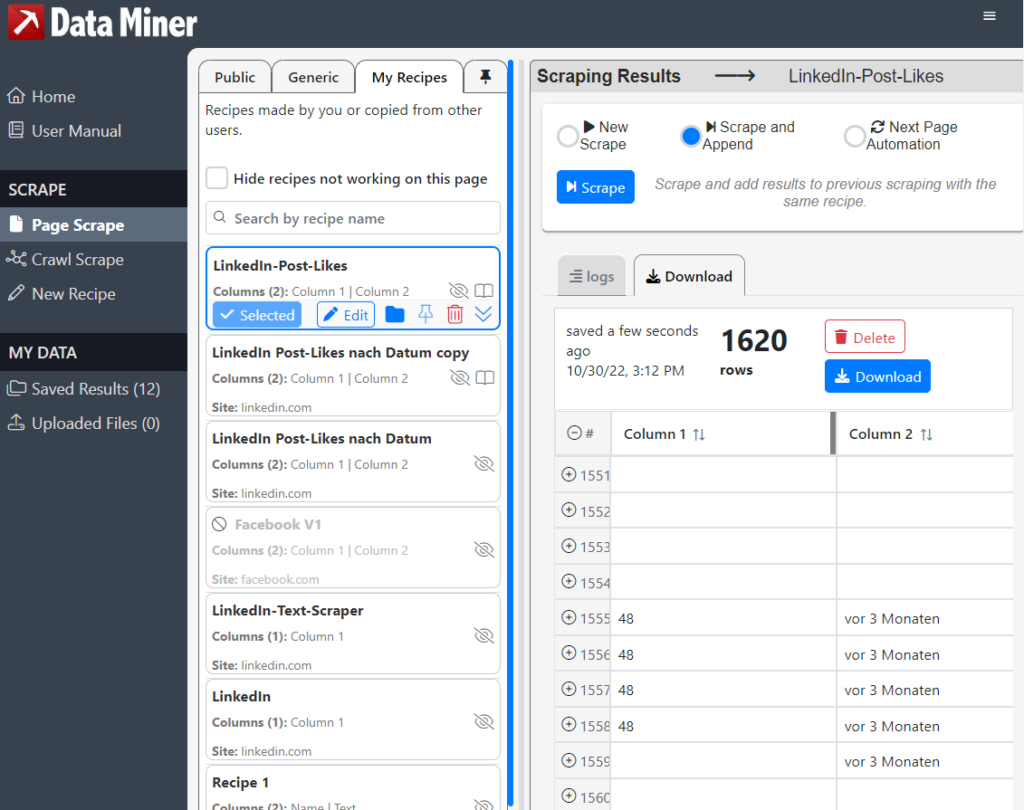

Schritt 6 – Tabelleneinträge ordnen
Gerade bei LinkedIn-Posts kommt es vor, dass Einträge zu denselben Beiträge mehrfach in die Tabelle aufgenommen werden. Um das zu bereinigen, solltet ihr entsprechend die Duplikate automatisch entfernen, sowie die Leerzeilen automatisch entfernen.
Duplikate entfernen – geht oben Menü unter dem Punkt Daten > Datenbereinigung > Duplikate entfernen
Leerzeilen entfernen – erstellt einen Filter in der Kopfzeile > wählt das Filter-Dropdown-Menü bei Column 1 aus > entfernt das Häkchen bei (Leer)
Anschließend noch die Daten entlang der Zeitachsenhierarchie sortiert und fertig: Schon haben wwir eine Aufschlüsselung der Beitragsreaktionen eines LinkedIn-Accounts.

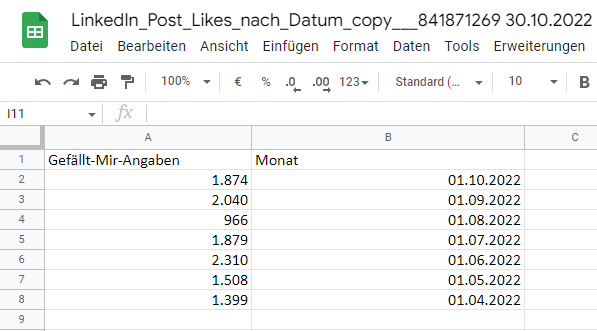
Für eine stringentere Darstellung können wir nun die Summen für einzelne Montate bilden, damit sich die Daten übersichtlicher und aussagekräftiger in Diagrammen darstellen lassen.

Du hast eine frage?
Stelle deine Frage


Slava Wagner
SEA, Paid Media, Conversion-Rate-Optimierung, Markt- und Trendanalysen.
info@slavawagner.de
+49 176 588 744 04
Inhalt
-
Tiefenanalysen und volle Unabhängigkeit via Data Scraping mit Data Miner
-
Schritt 1 – Data Miner installieren und aufrufen
-
Schritt 2 – Multiple Rows von Data Miner
-
Schritt 3 – Page & Easy Row Finder von Data Miner
-
Schritt 4 – Columns & Easy Column Finder von Data Miner
-
Schritt 5 – Navigation festlegen mit Easy Nav Finder von Data Miner
-
Schritt 6 – Tabelleneinträge ordnen
Das könnte dich auch interessieren:
Youtube SEO mit TubeBuddy und Ahrefs: Beschreibungen, Titel und Tags optimieren
Keywords mit Suchvolumen-Daten gibt es nicht nur für die organische Google-Suche, sondern auch für Youtube-Keywords.
Lead Syncing für Leadformulare aus Google Ads, LinkedIn Ads und Facebook Ads aufsetzen
Dieser Guide ist praktisch für Unternehmen, die kein CRM nutzen, aber trotzdem Leads aus Leadformularen per Mailversand bekommen möchten.