Sentimentanalysen
IBM Watson Natural Language Unterstanding (NLU) mit Google Colaboratory
Nie war es einfacher als heute, Cloud-Anwendungen zu bedienen: Google Colaboratory macht es möglich. Damit kannst du problemlos auf die IBM Cloud zugreifen und IBM Watson Natural Language Understanding nutzen, um selbst Sentimentanalysen aus Anzeigentexten, Websites, Mails oder Social-Media-Posts zu erstellen.
Schon kleine Veränderungen der Wortwahl erschaffen ein anderes emotionales Gesamtbild beim Gegenüber.
AI COnsulting
AI Automation Kit
– im Online Marketing
Mit diesen Make-Templates kannst du viele wichtige Marketing-Prozesse automatisieren und erhebliche personelle Ressourcen einsparen.
Ein harmlos wirkendes Adjektiv kann im Gesamtkontext eine negative Konnotation annehmen, und Passivsätze können eine gewisse Zaghaftigkeit nach außen kommunizieren, während Aktiv-Sätze positiver wirken. Für einen Menschen ist es dabei denkbar schwierig, aus einem größeren Textblock Emotionen belastbar und unvoreingenommen zu identifizieren.
IBM Watson Natural Language Understanding (NLU) macht es möglich: Die Anwendung auf der IBM Cloud ist einer der führenden Technologien für textbasierte Sentimentanalysen und Emotionsanalysen – basierend auf korpuslinguistischen Datensätzen und trainierten Sprachdaten.
Doch wofür ist das besonders relevant? Klar, es lassen sich mit IBM Watson Natural Language Understanding (NLU) alle möglichen Texte analysieren. Doch besonders wichtig ist die Anwendung für das Planen von Werbeanzeigen im Online Marketing, für Website-Texte, Marketing-Mails und Social-Media-Posts. Eine genauere Analyse kann hier schnell zutage bringen, dass bestimmte Emotionen oder eine positivere Tonalität tatsächlich mit einer besseren Performance korrelieren. Aus diesem Grund sind textbasierte Sentimentanalysen und Emotionsanalysen eine sehr spannende Sache.
Doch die Bedienung von IBM Watson Natural Language Understanding (NLU) hat zwei Nuancen: Sie findet auf der IBM Cloud statt, und wie in jeder Cloud, erhältst du dort lediglich deinen API-Schlüssel und eine URL. Von dort aus musst du dann selbstständig die Befehle aus der Dokumentation der IBM Cloud verwenden, um auf die Anwendung zuzugreifen und Sentimentanalysen durchzuführen.
Demo von IBM Watson Natural Language Understanding (NLU)
IBM selbst hat für IBM Watson Natural Language Understanding (NLU) eine Demo veröffentlicht, die auch ohne ein Konto in der IBM Cloud bedient werden kann. In der Emotionsanalyse wird der Text auf die Intensität von fünf Emotionen hin untersucht: Sadness, Joy, Fear, Disgust und Anger. In der Sentimentanalyse wird hingegen der Grad an positiver oder negativer Tonalität des Gesamtdokuments ausgegeben. Außerdem können Texte anhand ihrer Semantik kategorisiert werden in ihre Einordnungen, welche Ober- und Unterthemen sie bedienen.
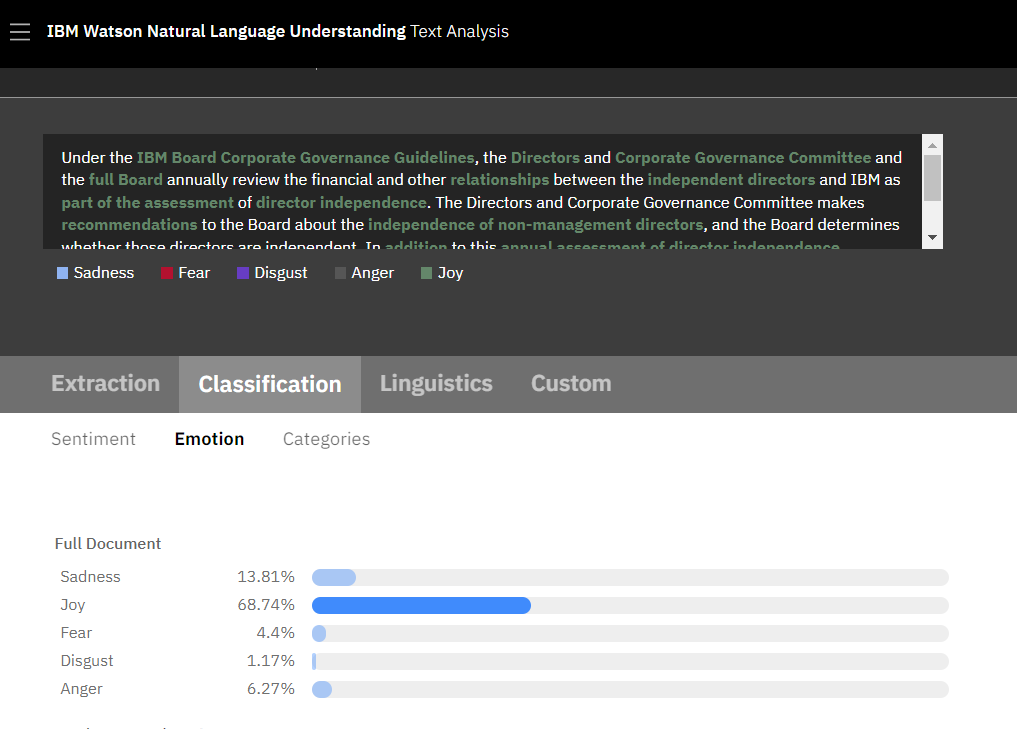
IBM Watson Natural Language Understanding (NLU) analysiert fünf Emotionen: Sadness, Joy, Fear, Disgust und Anger. Die Prozentwerte geben das Vorkommen der Emotionen im zu analysierenden Text oder in der zu analysierenden Website an.
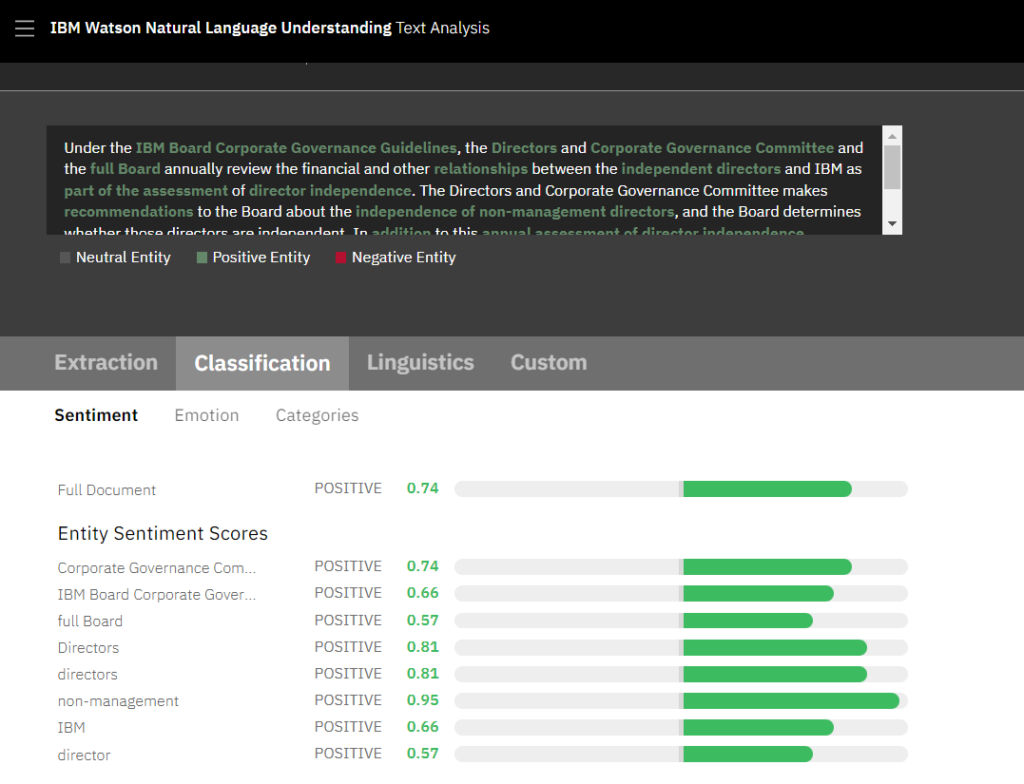
Die Sentimentanalyse von IBM Watson Natural Language Understanding (NLU) gibt an, wie positiv oder negativ die Tonalität des Dokuments ist, auf einer Skala von -100% bis +100%. Außerdem ist die Sentimentanalyse in der Lage, genau zu sagen, konkrete Sachgegenstand für welchen Ausschlag bei der Sentimentanalyse verantwortlich ist.
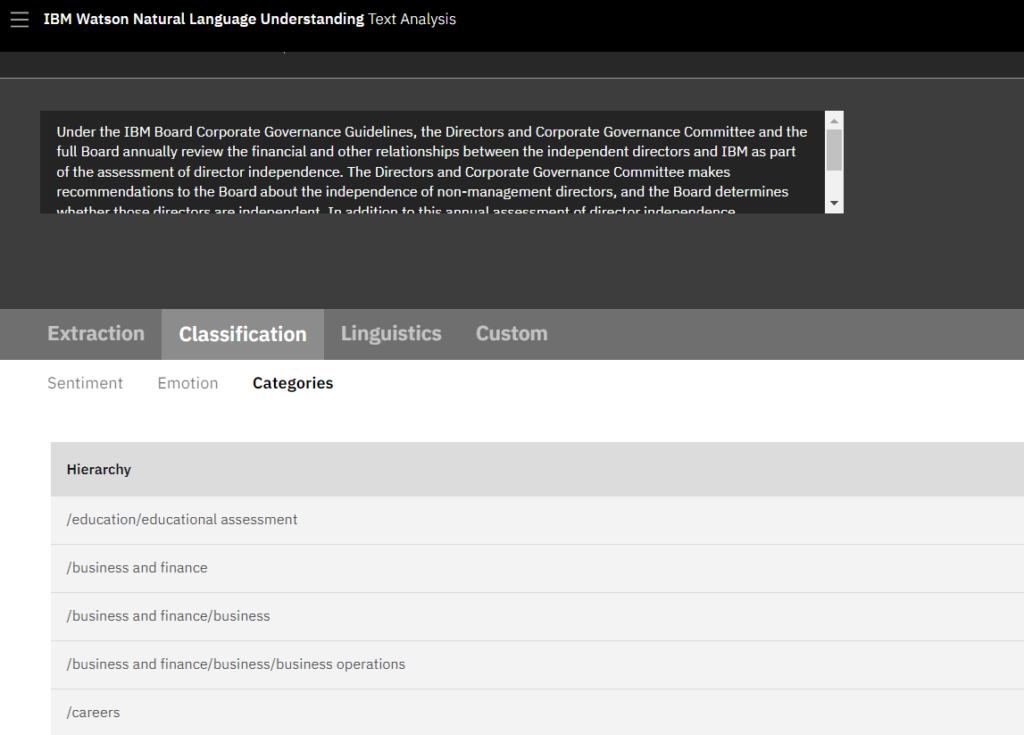
IBM Watson Natural Language Understanding (NLU) ist auch in der Lage, auf semantischer Ebene einen Text oder eine Website in Ober- und Unterthemen zu kategorisieren, und gibt dazu auch die statistische Wahrscheinlichkeit auf die Belastbarkeit der Zuordnung an, wie wir noch später sehen werden.
AI COnsulting
AI Automation Kit
– im Online Marketing
Mit diesen Make-Templates kannst du viele wichtige Marketing-Prozesse automatisieren und erhebliche personelle Ressourcen einsparen.
IBM-Konto erstellen und IBM Watson Natural Language Understanding (NLU) aktivieren
Wenn du die Vollversion von IBM Watson Natural Language Understanding (NLU) nutzen möchtest, geht das bereits mit dem kostenlosen Lite-Konto von IBM, wo du noch nicht einmal Kreditkartendaten hinterlegen musst. Bevor wir also auf die Bedienung der Anwendung mit Google Colaboratory kommen, solltest du dir ein Konto bei IBM auf der offiziellen Produktseite erstellen und IBM Watson Natural Language Understanding (NLU) aktivieren.
Kopiere anschließend den API-Schlüssel und die URL, damit du anschließend auf IBM Watson Natural Language Understanding (NLU) mit Google Colaboratory zugreifen kannst.
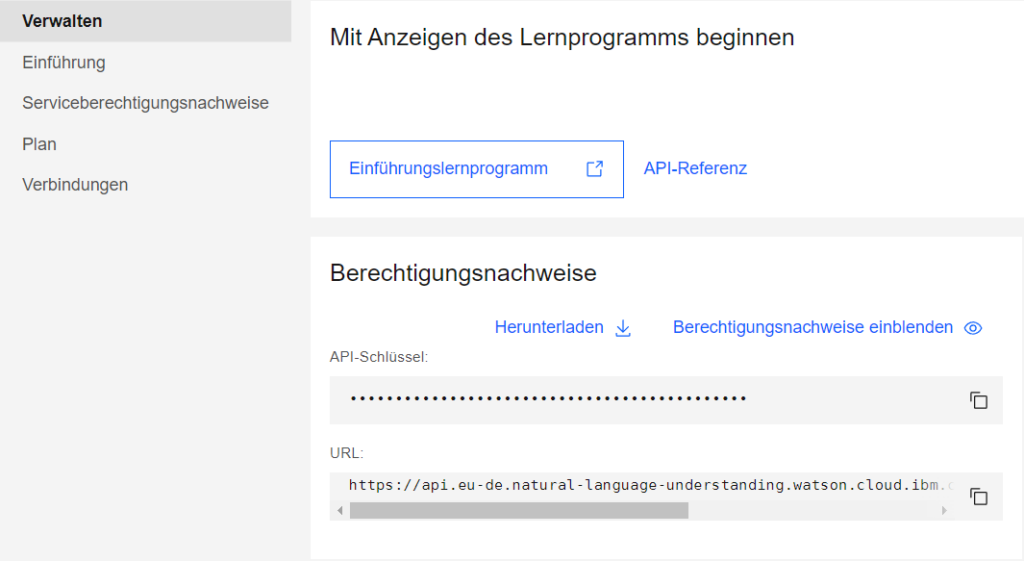
So sieht die IBM Cloud Console aus. Nachdem du dich für das kostenlose Lite-Paket von IBM registriert hast und du IBM Watson Natural Language Understanding (NLU) aktiviert hast, solltest du dir in der Ressourcenverwaltung den API-Schlüssel und die URL kopieren, damit du anschließend mit Google Colaboratory auf die Anwendung zugreifen kannst.
Google Colaboratory aktivieren für die Nutzung von IBM Watson Natural Language Understanding
Für den Zugang zur IBM Cloud benötigst du eine Umgebung, mit der du via Python-Befehlen textbasierte Analysen starten kannst. Keine Sorge: Das erfordert an sich keine Programmierkenntnisse, da die Eingabebefehle allesamt bezugsfertig in der Dokumentation von IBM Watson Natural Language Understanding (NLU) liegen. Du musst nur jeweils den API-Schlüssel ersetzen, sowie die URL, die du aus der Cloud Console zuvor kopiert hast, sowie natürlich deinen zu analysierenden Text.
Als Umgebung für das Einsetzen der Python-Befehle kannst du zum Beispiel Anaconda kostenlos herunterladen, und im Anaconda-Launcher ein Jupyter-Notebook auf deinem Rechner starten. Mit dieser Python-basierten Umgebung kannst du direkt den Zugang zur IBM Cloud herstellen. Im Jupyter-Notebook bei Anaconda ist auch standardmäßig das IBM Watson Studio vorinstalliert, sodass du direkt loslegen kannst.
Noch einfacher geht es mit Google Colaboratory (auch: Google Colab). Das ist ebenfalls ein Python-Notebook, mit dem du deine Python-Befehle aus der IBM Dokumentation eingeben kannst, um online auf die IBM Cloud zuzugreifen und IBM Watson Natural Language Understanding zu nutzen. Der Vorteil hier: Du brauchst keine Installation auf deinem Rechner durchzuführen, denn das Notebook von Google läuft im Browser. Es ist in der bereits vollkommen ausreichenden Standardversion komplett kostenlos und bietet dem Nutzer ein Laufwerk, auf dem alle Rechenoperationen stattfinden, und welches regelmäßig geleert werden kann. Und das Beste: Du kannst auf Google Colaboratory direkt über Google Drive zugreifen. Installiere einfach die entsprechende, kostenlose Google-Workspace-Erweiterung von Google Colaboratory, um das Python-Notebook von Google zu nutzen.
Gehe anschließend auf Google Colaboratory und klicke unter dem Menüreiter “Laufzeit” auf “Laufzeittyp ändern“.
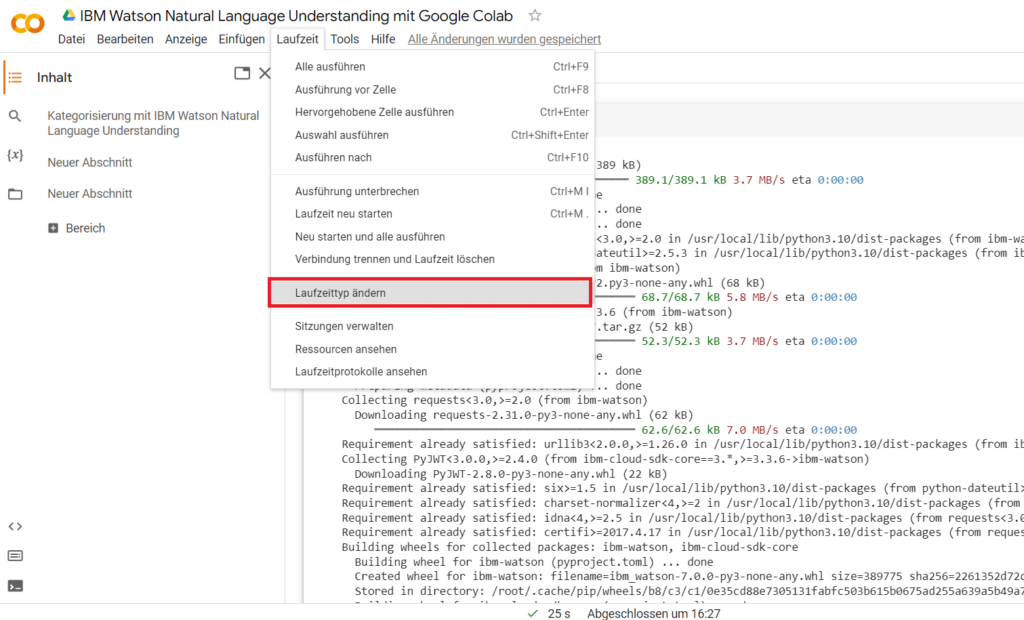
Ändere den Laufzeittyp in Google Colab.
Wähle nun “GPU” als Hardwarebeschleuniger aus, um eine schnellere Rechenleistung im Python-Notebook von Google Colaboratory zu erreichen.
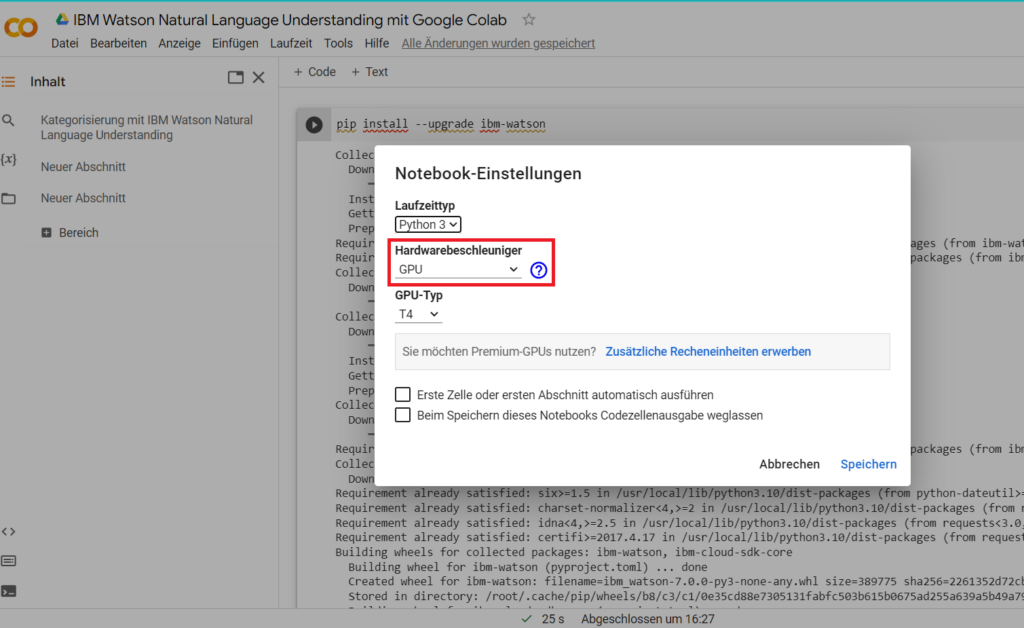
Setze den Hardwarebeschleuniger auf GPU.
AI COnsulting
AI Automation Kit
– im Online Marketing
Mit diesen Make-Templates kannst du viele wichtige Marketing-Prozesse automatisieren und erhebliche personelle Ressourcen einsparen.
Watson Developer Cloud Python SDK auf Google Colaboratory installieren
Bevor wir mit der Nutzung von IBM Watson Natural Language Understanding loslegen können, müssen wir zunächst das Paket Watson Developer Cloud Python SDK installieren. Das geht ganz einfach im Notebook von Google Colaboratory, und zwar mit dem Eingabebefehl: pip install –upgrade ibm-watson. Füge den Befehl ein und starte den Code über den entsprechenden Run-Button links in der Zeile.
pip install --upgrade ibm-watson
Der HubSpot-Kalender funktionier
Die Dokumentation von IBM Watson Natural Language Understanding (NLU)
Nun können wir damit beginnen, mit den Python-Befehlen aus der Dokumentation von IBM Watson Natural Language Understanding zu arbeiten. Wie bereits erwähnt funktioniert das Prinzip wie folgt: Die Angaben für den API-Schlüssel {apikey} und für die URL {url} müssten entsprechend durch die Angaben aus der IBM Cloud Console ersetzt werden. Starten wir nun mit einigen spannenden Anwendungsfällen:
Kategorisierungen von Websites mit IBM Watson Natural Language Understanding
Du kannst mit IBM Watson Natural Language Understanding (NLU) ganze Texte oder Websites kategorisieren lassen – in Ober- und Unterkategorien. Den Python-Befehl für Google Colaboratory für die Kategorisierung findest du hier in Dokumentation von IBM. In diesem Beispiel siehst du eine Kategorisierung einer Website durch die Gliederung in semantische Sachgegenstände.
import json
from ibm_watson import NaturalLanguageUnderstandingV1
from ibm_cloud_sdk_core.authenticators import IAMAuthenticator
from ibm_watson.natural_language_understanding_v1 \
import Features, CategoriesOptions
authenticator = IAMAuthenticator('{apikey}')
natural_language_understanding = NaturalLanguageUnderstandingV1(
version='2022-04-07',
authenticator=authenticator
)
natural_language_understanding.set_service_url('{url}')
response = natural_language_understanding.analyze(
url='https://www.more-fire.com/',
features=Features(categories=CategoriesOptions(limit=3))).get_result()
print(json.dumps(response, indent=2))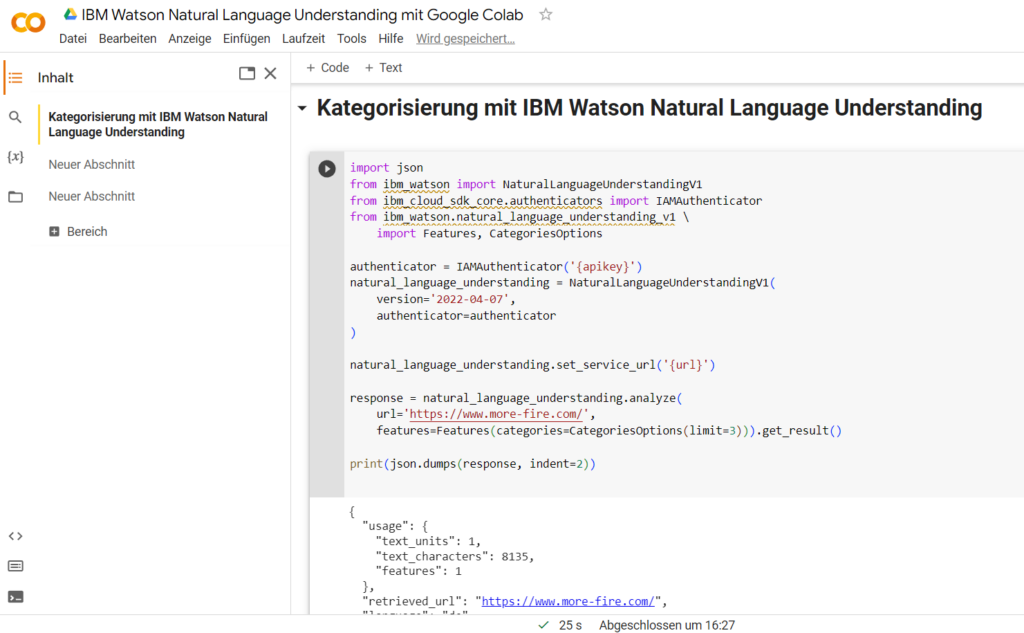
So würde der Python-Befehl für die Kategorisierung einer Website mit IBM Watson Natural Language Understanding (NLU) in Google Colaboratory in der Praxis aussehen.
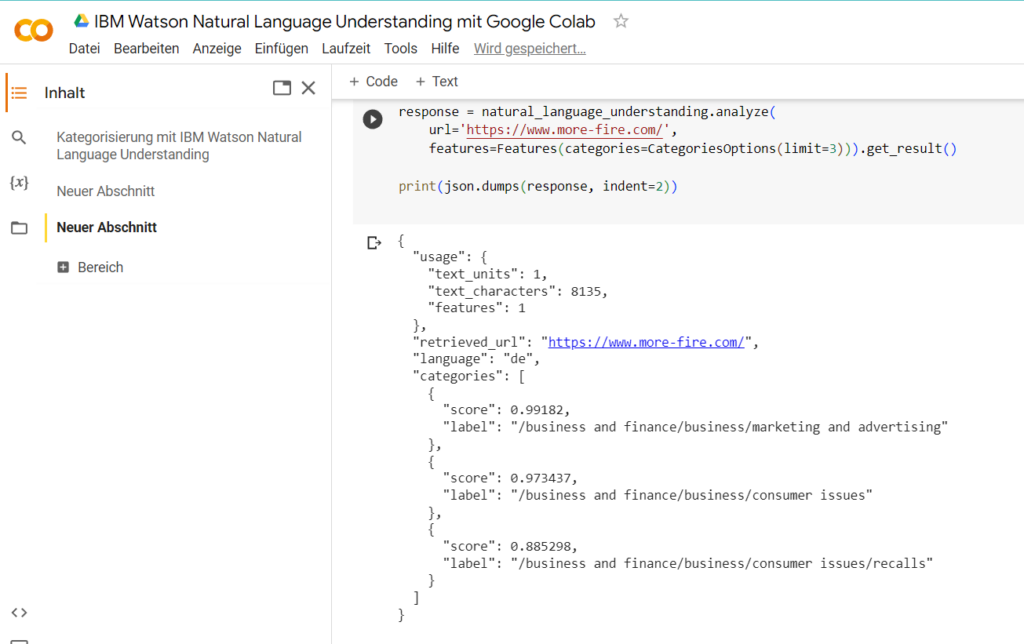
So würde das Ergebnis der Kategorisierung einer Website mit IBM Watson Natural Language Understanding (NLU) via Google Colaboratory aussehen.
Das Endergebnis der Kategorisierung der untersuchten Beispiel-Website ist also, dass sie im Business- und Finanzbereich angesiedelt ist und sich konkret mit Marketing und Werbung beschäftigt. Die Dezimalstellenwerte von “score” beschreiben entsprechend die prozentuale Wahrscheinlichkeit für das Zutreffen dieser Kategorisierung. Wie du siehst, errechnet IBM Watson Natural Language Understanding (NLU) nicht nur eine Möglichkeit, sondern mehrere Kategorisierungen und gibt hierfür prozentualen Wert für die Sicherheit der Einordnung in Dezimalzahlen an.
"categories": [
{
"score": 0.99182,
"label": "/business and finance/business/marketing and advertising"
},
{
"score": 0.973437,
"label": "/business and finance/business/consumer issues"
},
{
"score": 0.885298,
"label": "/business and finance/business/consumer issues/recalls"
}AI COnsulting
AI Automation Kit
– im Online Marketing
Mit diesen Make-Templates kannst du viele wichtige Marketing-Prozesse automatisieren und erhebliche personelle Ressourcen einsparen.
Emotionsanalyse eines Textes mit IBM Watson Natural Language Understanding
Kommen wir nun zum eigentlich Spannenden: Die Emotionsanalyse eines ganzen Textes mit IBM Watson Natural Language Understanding (NLU). Den zu analysierenden Text kannst du einfach in entsprechende Position des Python-Befehls aus der IBM Dokumentation einfügen. Bedenke aber: Die Emotionsanalyse funktioniert bei Texten in englischer Sprache reibungslos, auf Deutsch nicht. Wenn du also deutschsprachige Texte analysieren möchtest, übersetze sie vorher, um eine Emotionsanalyse mit IBM Watson Natural Language Understanding (NLU) durchzuführen. Ersetze auch hier – wie immer – die Stellen {apikey} und {url} mit den entsprechenden Credentials aus deinem IBM-Konto in der Cloud Console. Noch eine Sache ist wichtig: Neben den Gesamtwerten an Emotionen für den kompletten Text (“document”) kannst du noch für zwei gesonderte Sachgegenstände eine Analyse abfragen. Gib die zwei Sachgegenstände ein, bei (targets=[‘Sachgegenstand1’, ‘Sachgegenstand2’]).
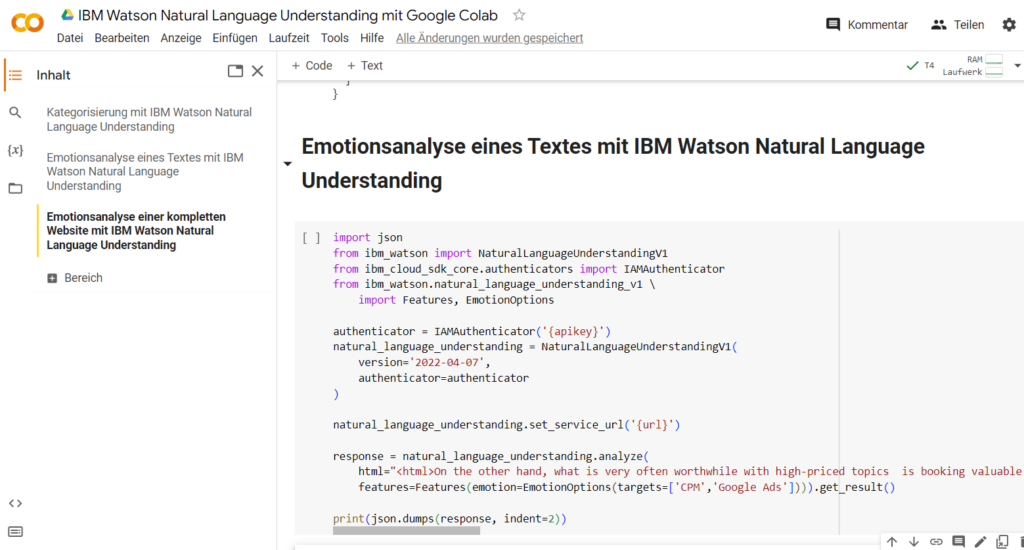
Python-Befehl aus der IBM Dokumentation für die Emotionsanalyse eines ganzen Textes mit IBM Watson Natural Language Understanding (NLU) in Google Colaboratory.
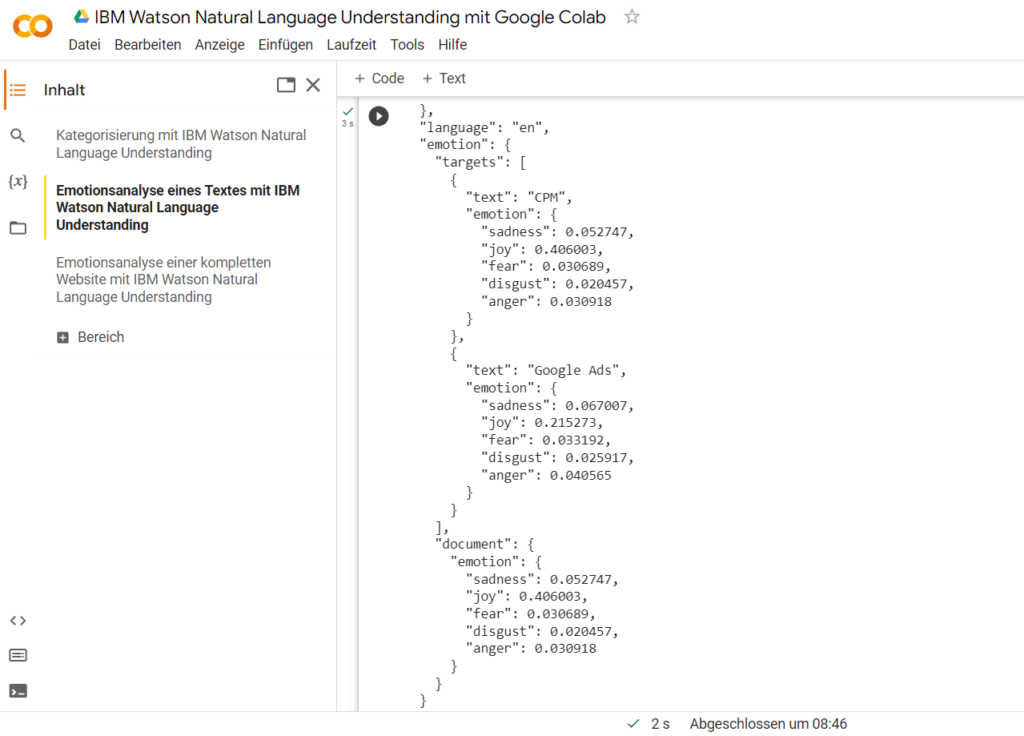
Das Ergebnis der Emotionsanalyse mit IBM Watson Natural Language Understanding (NLU) in Google Colaboratory. Wie du siehst, werden dir für die zwei separat zu untersuchenden Sachgegenstände die entsprechenden Werte für die fünf Emotionen in Dezimalzahlen angegeben (0% – 100%). Der wichtigste Abschnitt ist jedoch “document”, denn hier steht der Gesamtwert für das komplette zu untersuchende Dokument (Text oder Website).
Im Abschnitt “document” siehst du die Werte der Emotionsanalyse des Textes von IBM Watson Natural Language Understanding (NLU) für den kompletten Text. Daher ist das für Analysezwecke der wichtigste Wert. Die Daten sind wie immer in Dezimalzahlen angegeben und stellen das prozentuale Vorkommen der Emotionen dar (0% – 100%).
"document": {
"emotion": {
"sadness": 0.052747,
"joy": 0.406003,
"fear": 0.030689,
"disgust": 0.020457,
"anger": 0.030918Emotionsanalyse von Websites mit IBM Watson Natural Language Understanding
Nach demselben Schema kannst du auch eine Emotionsanalyse mit IBM Watson Natural Language Understanding (NLU) für eine ganze Website durchführen. Dafür müsstest du den Code manuell anpassen. Das hier wäre der von mir angepasste Code zum Einsetzen:
import json
from ibm_watson import NaturalLanguageUnderstandingV1
from ibm_cloud_sdk_core.authenticators import IAMAuthenticator
from ibm_watson.natural_language_understanding_v1 \
import Features, EmotionOptions
authenticator = IAMAuthenticator('{apikey}')
natural_language_understanding = NaturalLanguageUnderstandingV1(
version='2022-04-07',
authenticator=authenticator
)
natural_language_understanding.set_service_url('{url}')
response = natural_language_understanding.analyze(
url='https://www.ogilvy.com/',
features=Features(emotion=EmotionOptions(targets=['advertising','pr']))).get_result()
print(json.dumps(response, indent=2))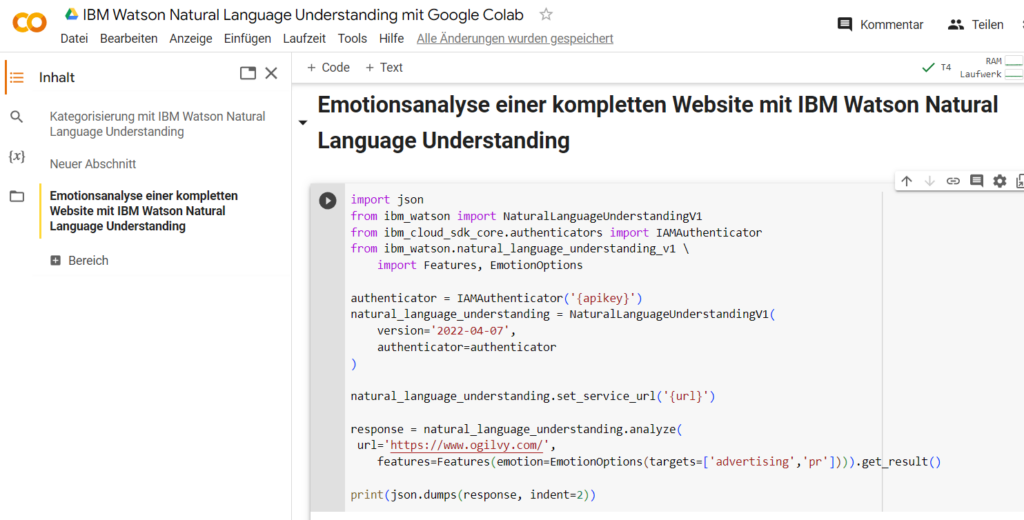
So würde die Emotionsanalyse einer ganzen Website mit IBM Watson Natural Language Understanding (NLU) via Google Colaboratory aussehen.
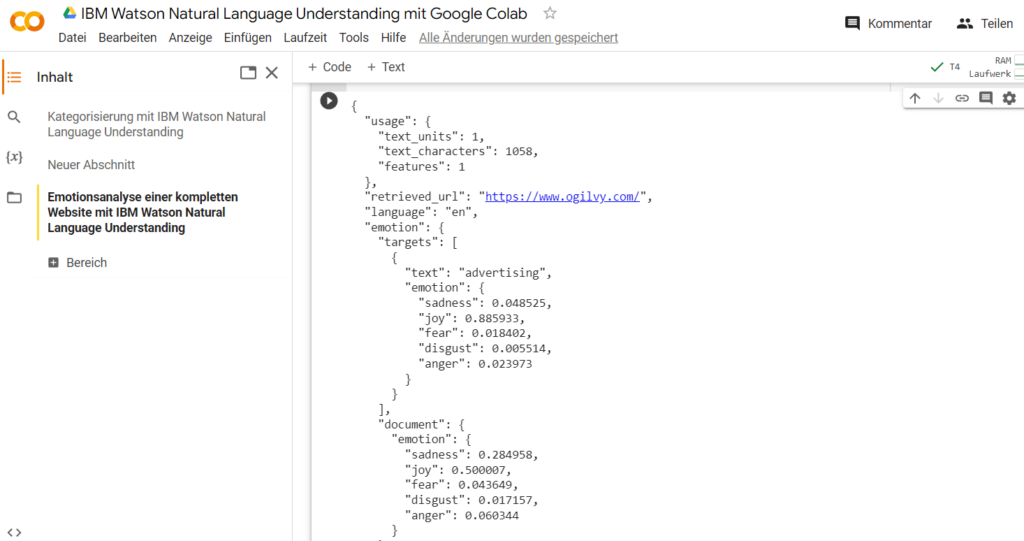
Das wären die Ergebnisse der Emotionsanalyse mit IBM Watson Natural Language Understanding (NLU) im Python-Notebook von Google Colaboratory.
Auch findest du die wichtigsten Werte im Abschnitt “document“, der das Vorkommen der fünf Emotionen bei IBM Watson Natural Language Understanding (NLU) für das gesamte Dokument in Dezimalstellen (prozentualer Score) indiziert.
"document": {
"emotion": {
"sadness": 0.284958,
"joy": 0.500007,
"fear": 0.043649,
"disgust": 0.017157,
"anger": 0.060344AI COnsulting
AI Automation Kit
– im Online Marketing
Mit diesen Make-Templates kannst du viele wichtige Marketing-Prozesse automatisieren und erhebliche personelle Ressourcen einsparen.
Sentimentanalyse von Websites mit IBM Watson Natural Language Understanding
Eine Sentimentanalyse unterschiedet sich von der Emotionsanalyse dahingehend, dass hier nicht konkrete Emotionen analysiert werden, sondern die positive oder negative Tonalität des Textes oder der Website-URL auf einer Skala -100% bis +100%. Den entsprechenden Python-Befehl für die Sentimentanalyse mit IBM Watson Natural Language Understanding (NLU) findest du hier in der IBM Dokumentation. Ersetze wie immer den API-Schlüssel und die URL durch deine eigenen Credentials aus der IBM Cloud Console und verwende den Code in Google Colaboratory, um deine eigene Sentimentanalyse durchzuführen. Du kannst auch hier einen konkreten Sachgegenstand hervorheben, der speziell analysiert werden soll, damit du neben den Gesamtwerten für das Dokument auch die Werte für diesen Sachgegenstand erhältst.
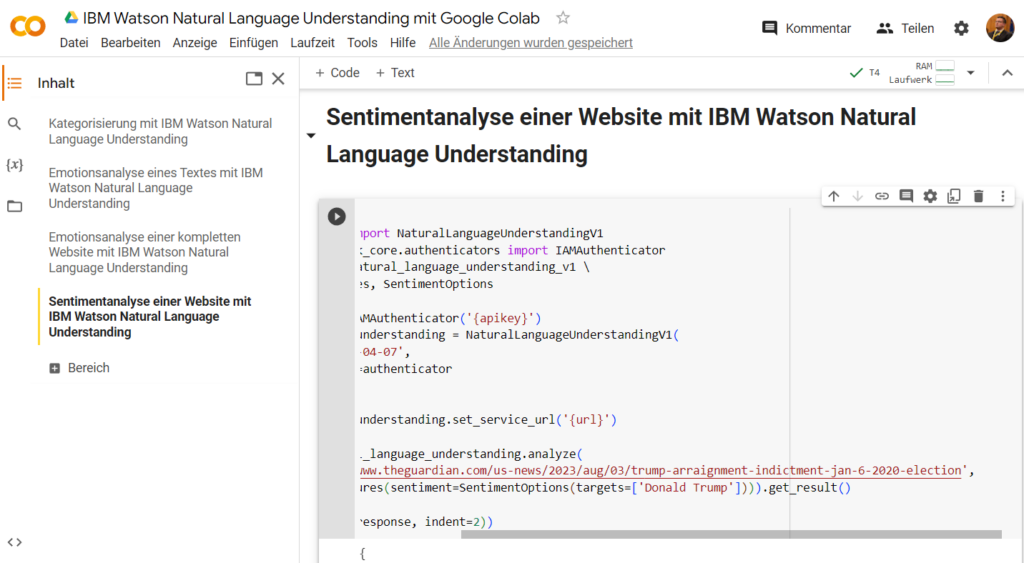
So sieht ein Python-Befehl für die Sentimentanalyse einer kompletten Website-URL in IBM Watson Natural Language Understanding (NLU) via Google Colaboratory aus.
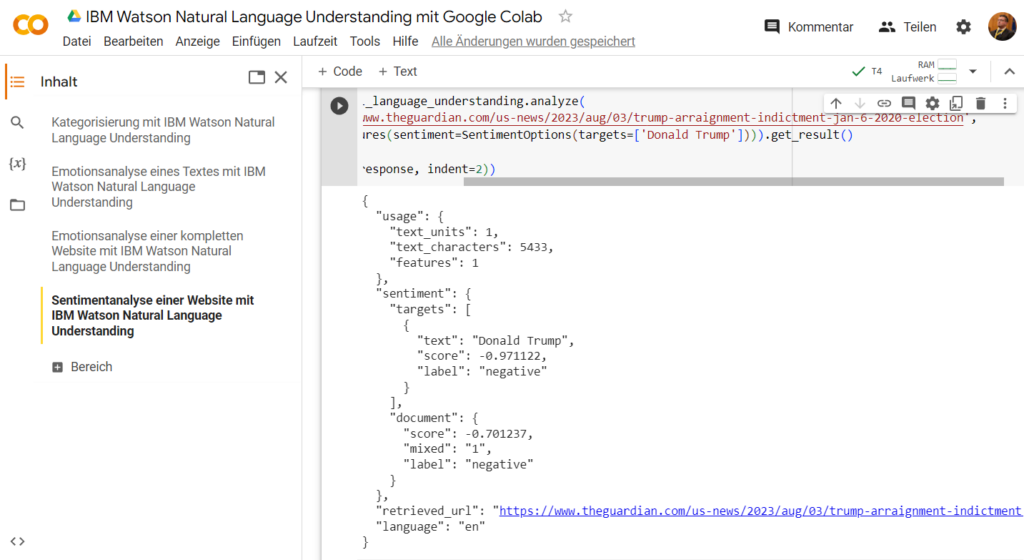
Das sind die Ergebnisse der Sentimentanalyse mit IBM Watson Natural Language Understanding (NLU) mittels Google Colaboratory.
In diesem Beispiel wurde ein Guardian-Artikel über Donald Trump mit IBM Watson Natural Language Understanding (NLU) auf die Sentiment-Werte hin analysiert. Als speziell hervorgehobener Sachgegenstand ist hier “Donald Trump” genannt. Wie du siehst, ist sowohl für den Sachgegenstand “Donald Trump” als auch für das gesamte Dokument der Sentiment-Wert sehr negativ, mit einer Tonalität fürs Gesamtdokument von rund -70% und für den Sachgegenstand “Donald Trump” mit rund -97%.
"sentiment": {
"targets": [
{
"text": "Donald Trump",
"score": -0.971122,
"label": "negative"
}
],
"document": {
"score": -0.701237,
"mixed": "1",
"label": "negative"
}
}Google Colaboratory mit Google Sheets verknüpfen
Da du auf Google Colaboratory sowieso über Google Drive zugreifen kannst, bietet es sich an, deine Datensätze aus Google Sheets direkt ans Python-Notebook von Google anzuschließen. Du kannst mit den entsprechenden Befehlen aus der gspread library Google-Sheets-Daten importieren oder exportieren. Wenn du also Texte aus Social-Media-Posts, aus Anzeigen oder aus Websites in Google Sheets hinterlegt oder gescraped hast, kannst du dir somit eine Brücke bauen, um diese Texte direkt zu Google Colaboratory importieren zu lassen und nach der Analyse mit IBM Watson Natural Language Unterstanding (NLU) wieder zu exportieren.
Mit dem nachfolgenden Python-Befehl kannst du beispielsweise Daten aus Google Sheets in Google Colaboratory importieren und formatieren. Den Code findest du hier.
from google.colab import auth
auth.authenticate_user()
import gspread
from google.auth import default
creds, _ = default()
gc = gspread.authorize(creds)
worksheet = gc.open('Your spreadsheet name').sheet1
# get_all_values gives a list of rows.
rows = worksheet.get_all_values()
print(rows)
# Convert to a DataFrame and render.
import pandas as pd
pd.DataFrame.from_records(rows)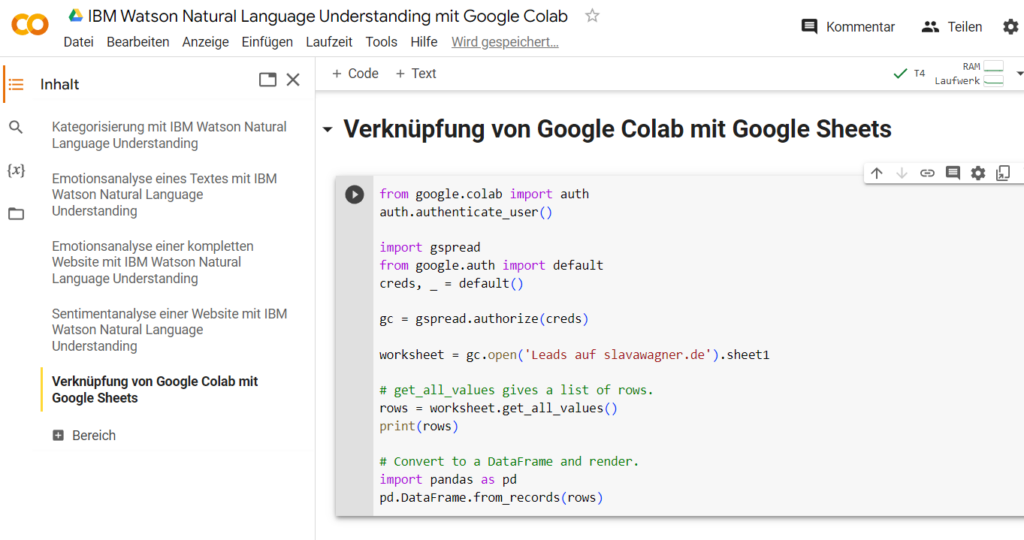
Mit diesem Python-Befehl aus der gspread library kannst du eine Tabelle aus Google Sheets zu Google Colaboratory importieren und formatieren. Aus dieser Weise kannst du beispielsweise einige zu analysierende Texte für Emotions- und Sentimentanalysen mit IBM Watson Natural Language Understanding (NLU) direkt in Google Colaboratory ziehen. Mit dem entsprechenden Code kannst du die Werte der Analysen auch wieder in in eine Google-Sheets-Tabelle exportieren lassen.
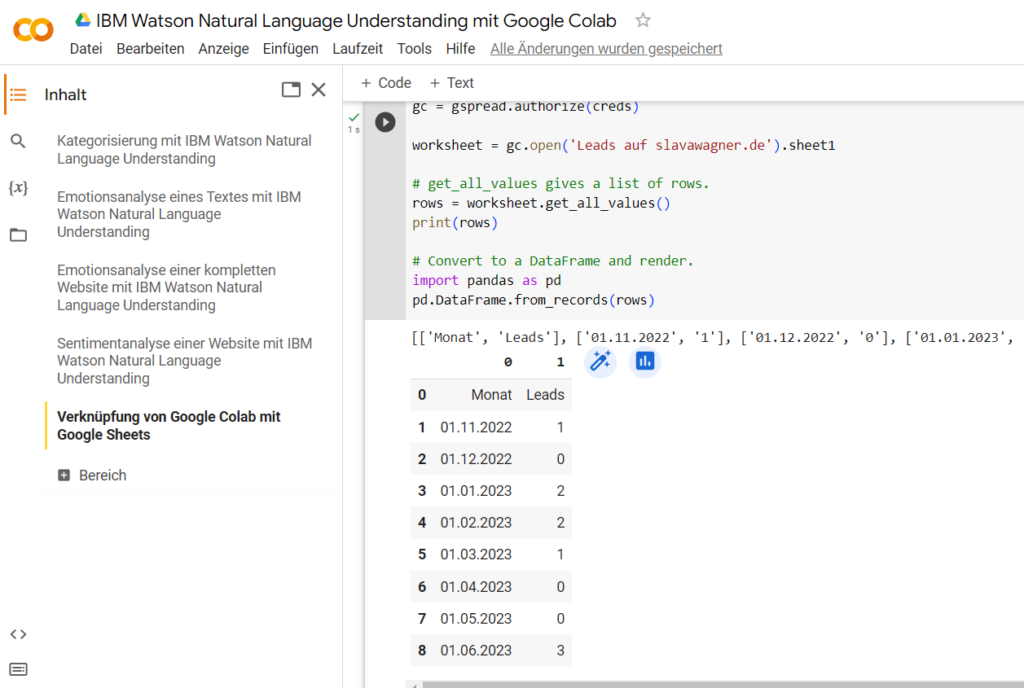
Beispiel-Import von einfachen Werten aus einer Google-Sheets-Tabelle in Google Colaboratory.
AI COnsulting
AI Automation Kit
– im Online Marketing
Mit diesen Make-Templates kannst du viele wichtige Marketing-Prozesse automatisieren und erhebliche personelle Ressourcen einsparen.

Inhalt
- Demo von IBM Watson Natural Language Understanding (NLU)
- IBM-Konto erstellen und IBM Watson Natural Language Understanding (NLU) aktivieren
- Google Colaboratory aktivieren für die Nutzung von IBM Watson Natural Language Understanding
- Watson Developer Cloud Python SDK auf Google Colaboratory installieren
- Die Dokumentation von IBM Watson Natural Language Understanding (NLU)
- Kategorisierungen von Websites mit IBM Watson Natural Language Understanding
- Emotionsanalyse eines Textes mit IBM Watson Natural Language Understanding
- Emotionsanalyse von Websites mit IBM Watson Natural Language Understanding
- Sentimentanalyse von Websites mit IBM Watson Natural Language Understanding
- Google Colaboratory mit Google Sheets verknüpfen
Das könnte dich auch interessieren:
HubSpot Kalender für Leadgenerierung — mit Google Ads und Conversion-Wert-Export von Customer-Daten
Der HubSpot-Kalender ist ähnlich wie Calendly: Du kannst ihn auf deiner Website installieren, damit Nutzer Termine buchen. Die Leads werden automatisch in HubSpot angelegt.
Calendly-Integration für die Website erstellen und Termine per E-Mail versenden mit HTML-Buttons
Mit Calendly kannst du schnell und unkompliziert Terminbuchungen für deine Online-Nutzer bereitstellen. Vorteil: Die Terminerscheinungsquote ist sehr hoch.